A simple use-case comparing OmicsBox with R chunks
The OmicsBox feature “Pairwise Differential Expression Analysis” is designed to perform differential expression analysis of count data arising from RNA-seq technology. This tool allows the identification of differential expressed genes considering two different conditions based on the software package ‘edgeR’, which belongs to the Bioconductor project. This use case shows the basic analysis workflow, comparing the results obtained with R Bioconductor and OmicsBox.
DataSet
This analysis describes a differential expression analysis of an RNA-Seq dataset from tomato (Solanum lycopersicum) pollen undergoing chronic heat stress. Samples and counts were obtained from the laboratory of Nurit Firon. The control plants (C1-C5) were grown at 28/18 ºC and the treatment samples (T1-T5) were grown at 32/26 ºC day/night. Each collection includes one treatment and one control sample consisting of pollen pooled from multiple plants.
Download:
Video tutorial:
Analysis Workflow
-
Loading Data
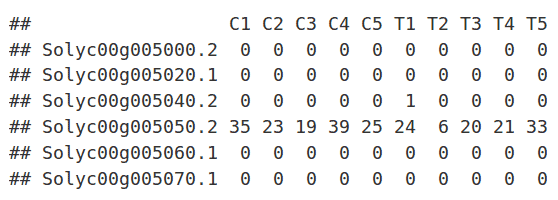
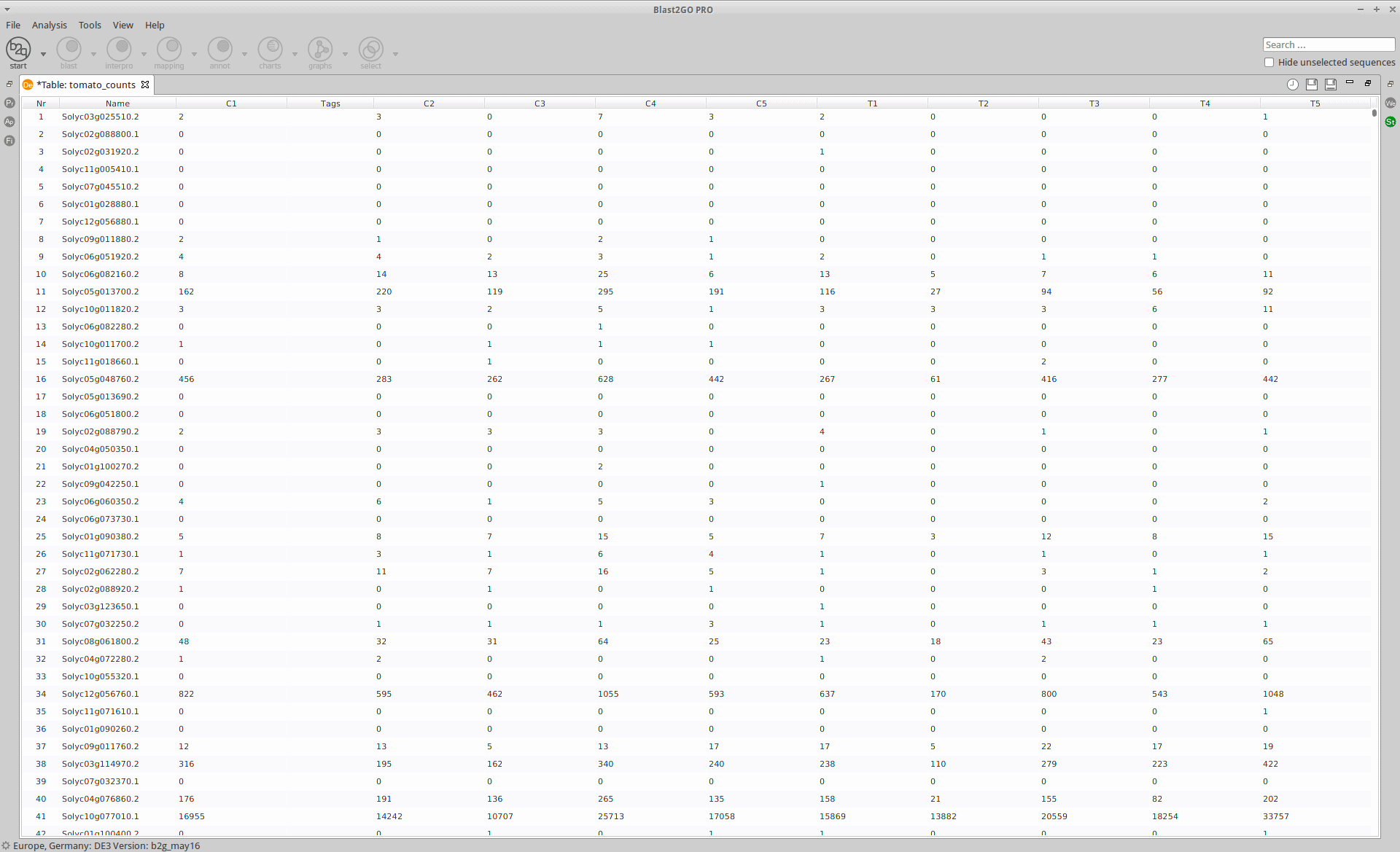
The read counts for the ten individual libraries were stored in one tab-delimited file. EdgeR only accepts raw counts without any type of normalization.
-
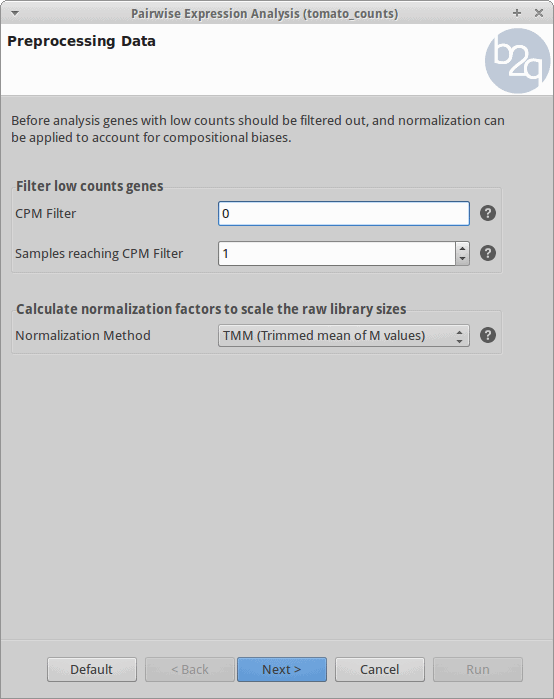
Filtering and Normalization
Genes with zero counts are eliminated since it makes no sense to test them for differential expression if they were not expressed. Normalization is applied to account for compositional difference between the libraries. Note that when normalization is applied in edgeR, the software does not change the counts. Instead, it calculates normalization factors that will be used later.
-
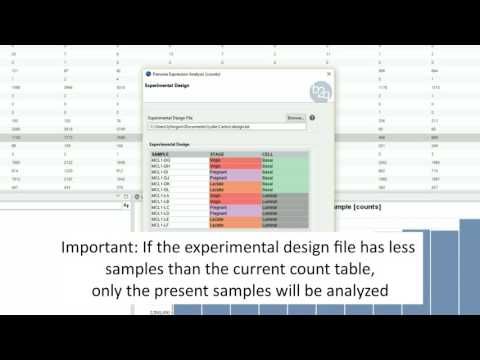
Experimental Design
The experimental design of this case corresponds to two experimental conditions, “Control” and “Treatment”, with five replicates each one.
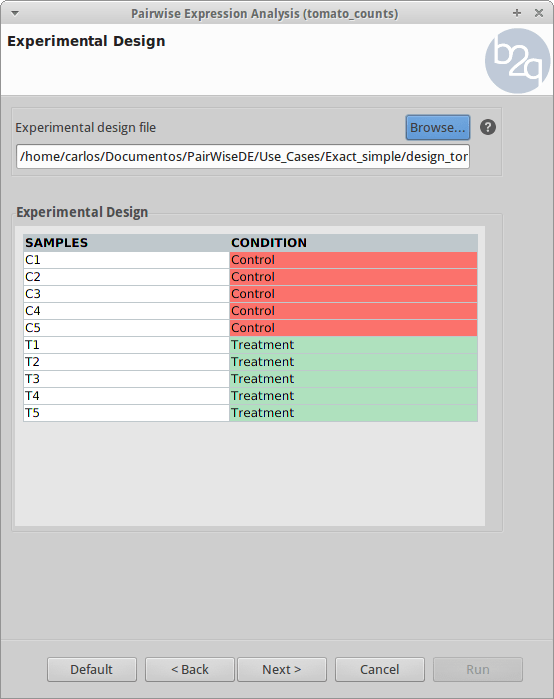
-
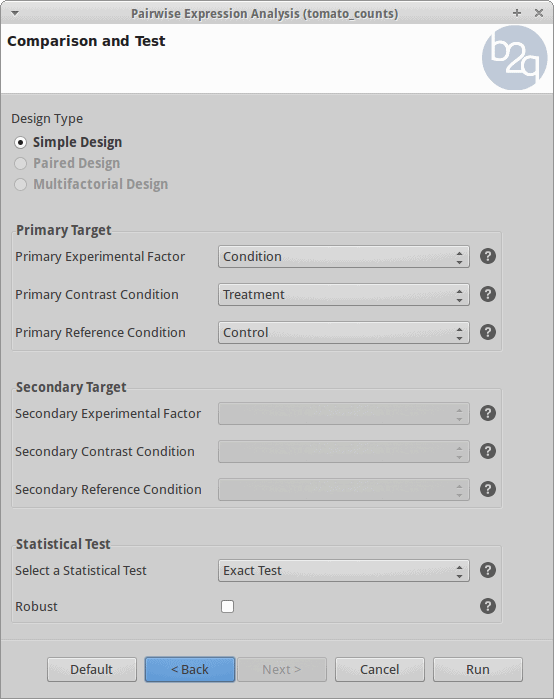
Comparison and Test
For the analysis, all the control and treatment samples will be treated as replicates in order to identify genes whose expression changed due to the heat stress treatment. This corresponds to what the edgeR manual calls the “classic approach” (Exact test).
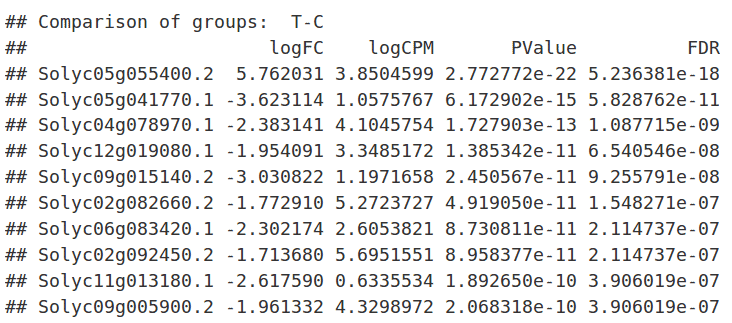
Results
After the analysis, interpretation of results is important to reach biological conclusions.

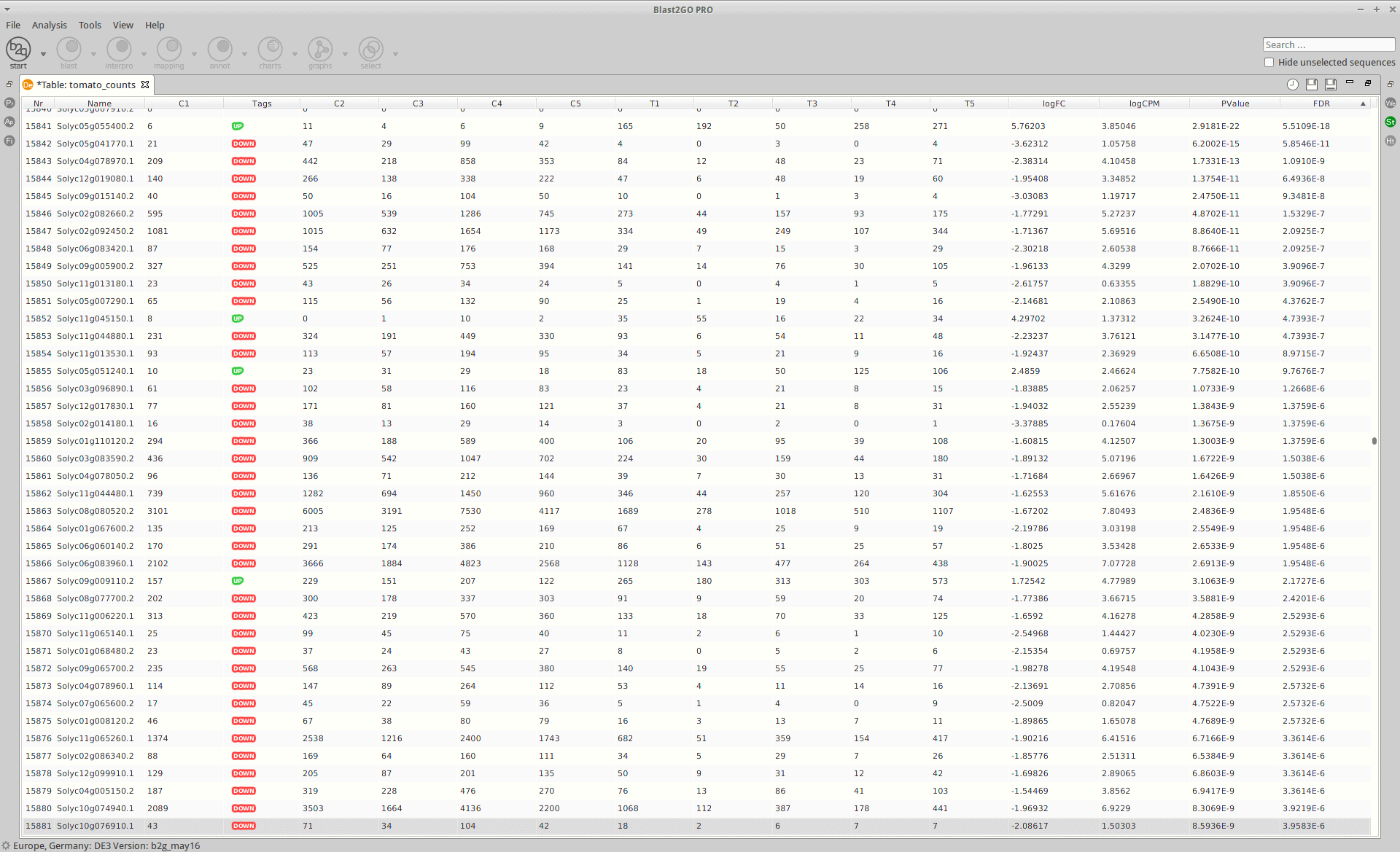
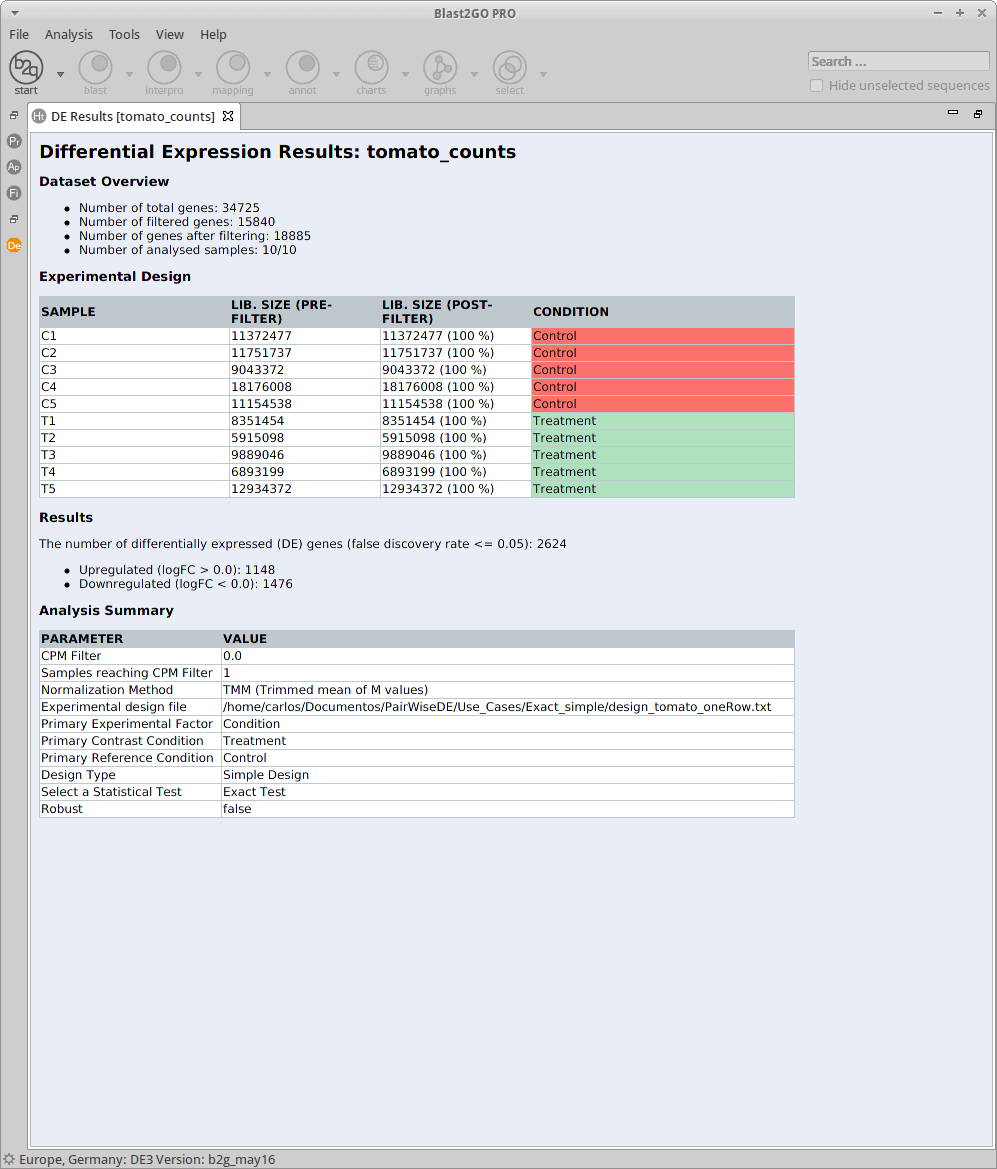
Statistics
-
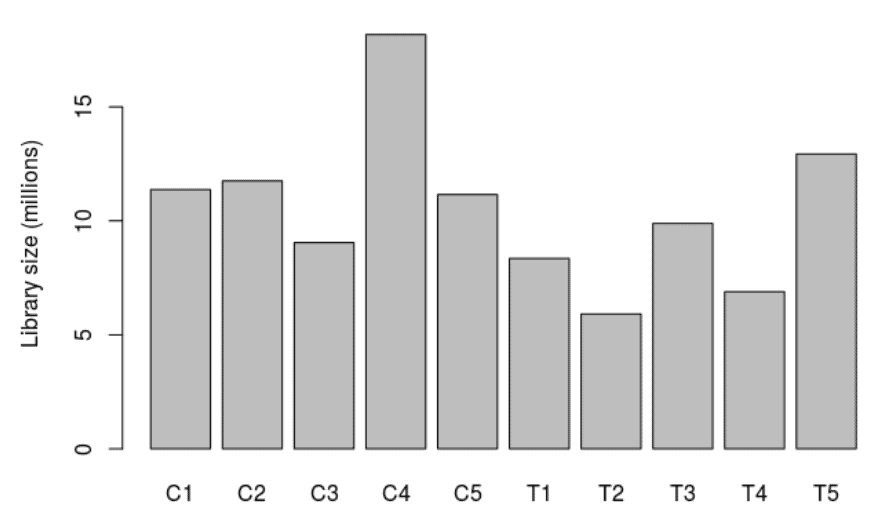
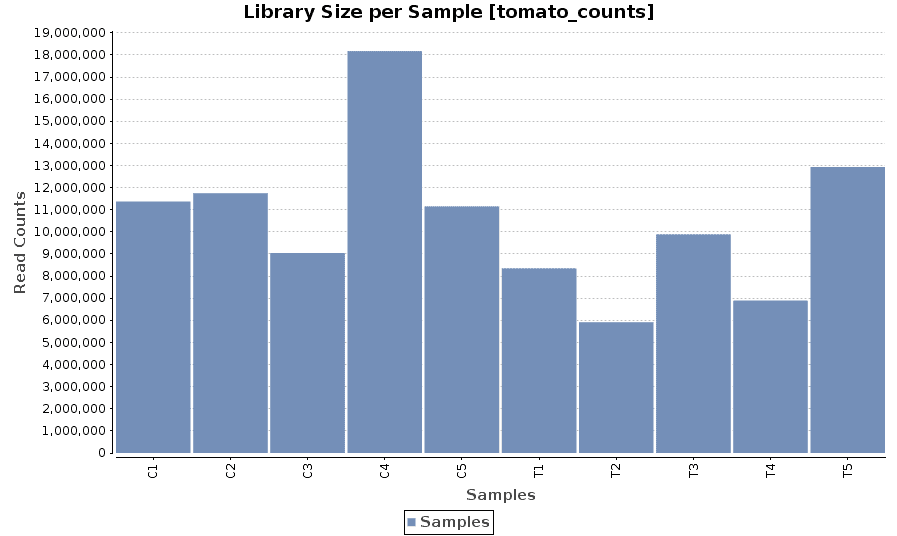
Library Size
A bar chart showing the read counts contained in each sample.
-
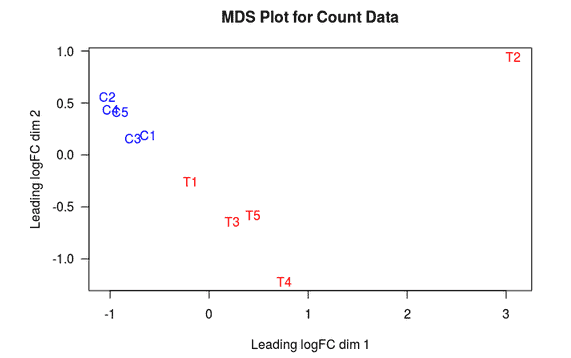
MDS Plot
A multi-dimensional scaling (MDS) plot can show similarity between samples in which distances correspond to leading log-fold-changes between each pair of RNA samples. The leading log-fold-change is the average (root-mean-square) of the largest absolute log-fold-changes between each pair of samples. This plot can be viewed as a type of unsupervised clustering.
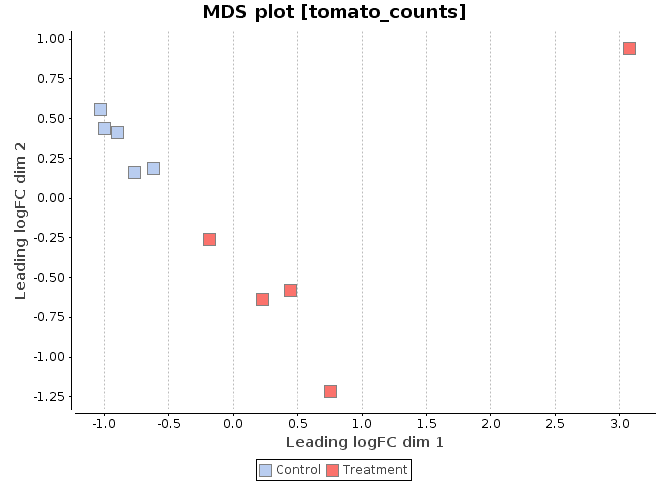
-
MA Plot
This chart illustrates the relationship between logFC and average expression level for the differential expressed genes, which are highlighted in red. The blue lines indicate genes that are up or down-regulated two fold.
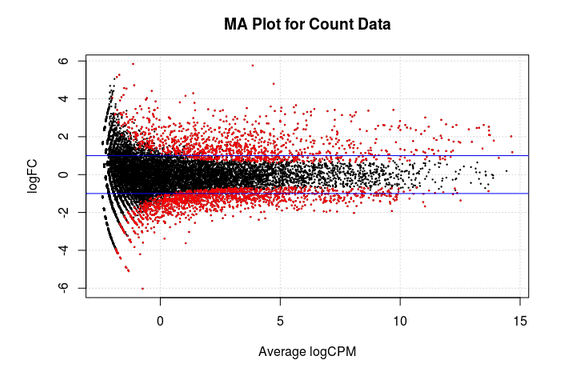
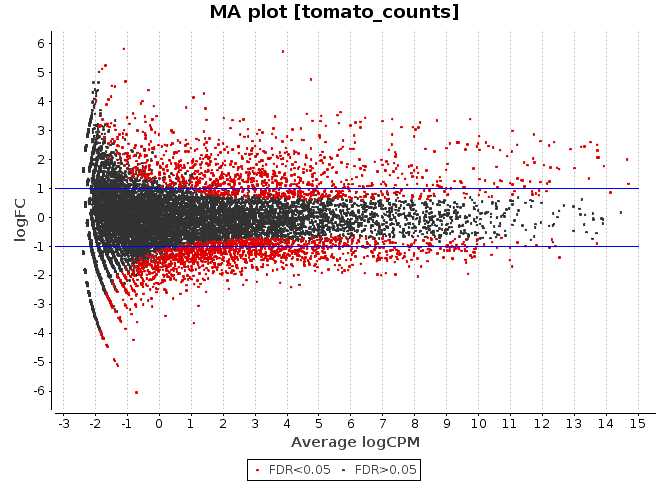
-
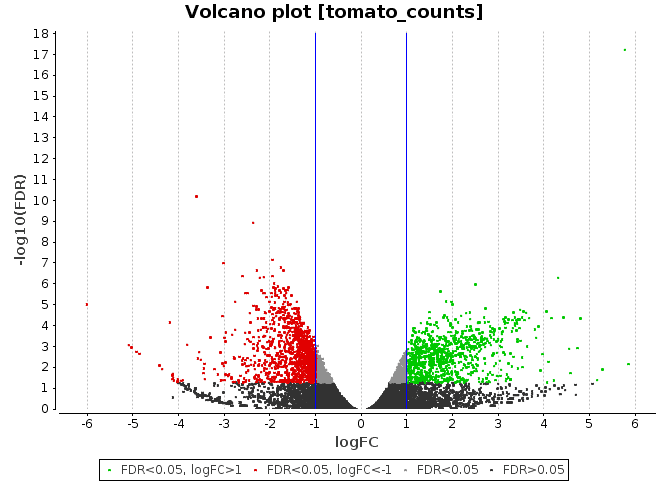
Volcano Plot
Scatter chart that is constructed by plotting the negative log of the adjusted p-values (FDR) on the y-axis versus the log of the fold changes on the x-axis.
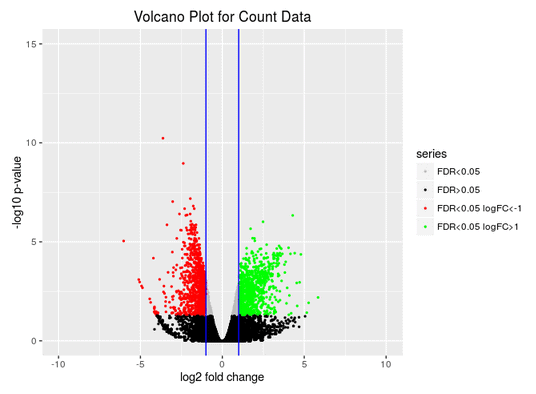
Conclusions
As shown in this use case, the edgeR package is a powerful tool that allows statistical analysis for RNA-seq technology data. The OmicsBox feature “Pairwise Differential Expression Analysis” uses all the edgeR statistical potential to offer an easy and simple way to perform this type of analysis, without requiring programming skills. Futhermore, users can take advantage of OmicsBox features to complete the analysis and achieve greater understanding of the biological problem that is being studied.
References:
Robinson MD, McCarthy DJ and Smyth GK (2010). “edgeR: a Bioconductor package for differential expression analysis of digital gene expression data.” Bioinformatics, 26, pp. -1.



